Học tự giám sát là gì
Trước tiên ta cần tìm hiểu qua khái niệm về mô hình học tự giám sát, nó sinh ra để giải quyết vấn đề gì.
Tại thời điểm 2020, khi ứng dụng của AI đã đi sâu vào các ứng dụng thực tiễn hơn là trên các bài báo nghiên cứu, khi các “ông lớn” trong ngành sản xuất bắt đầu tích hợp các giải pháp có sử dụng AI vào dây chuyền sản xuất, sự khan hiếm dữ liệu đang nổi lên như một thách thức lớn.
Không giống như các công ty về Internet hay dịch vụ điện tử, nơi có dữ liệu từ hàng tỷ người dùng để dễ dàng đào tạo các mô hình AI mạnh mẽ, việc thu thập một lượng dữ liệu lớn trong sản xuất thường không khả thi và tốn nhiều chi phí. Ví dụ, trong sản xuất ô tô, nơi mà các mô hình cải tiến năng suất và chất lượng (Lean Six Sigma) đã được áp dụng rộng rãi, hầu hết các nhà cung cấp hàng đầu và các OEM có ít hơn 3 đến 4 sản phẩm lỗi trên 1 triệu bộ phận.

Sự hiếm có của những dữ liệu lỗi này khiến cho việc huấn luyện các mô hình để kiểm tra trực quan và nhận biết chúng là rất khó khăn.
Áp dụng AI cho dữ liệu nhỏ như thế nào? Big Data đã hỗ trợ rất tốt để các công ty về Internet sử dụng các mô hình AI. Vậy với dữ liệu nhỏ cho các nhà sản xuất thì sao, làm thế nào để các mô hình AI hoạt động một cách hiệu quả? Những nghiên cứu tiến bộ mới nhất gần đây trong AI đang đưa điều này trở thành hiện thực. Và kỹ thuật học tự giám sát là một trong những kỹ thuật để khắc phục vấn đề về thiếu hụt dữ liệu ngay cả khi chỉ có một vài dữ liệu lỗi hoặc thậm chí ít hơn. Ngoài việc sử dụng các nhãn do chính con người gán nhãn, mô hình sẽ sử dụng thêm một lượng lớn các dữ liệu do chính nó gãn nhán cho việc học tập ở các bước và giai đoạn tiếp theo.
Ứng dụng trong bài toán chuyển đổi giọng nói thành văn bản
“Self-supervised speech recognition with limited amount of labeled data” là một dự án sử dụng kỹ thuật học tự giám sát để áp dụng vào bài toán chuyển đổi giọng nói thành văn bản. Hôm nay chúng ta sẽ chạy thử pretrained-model của dự án với ngôn ngữ tiếng Việt.

Các bạn vào google colab để tạo notebook Google Colab. Sau đó tải về bản pretrained-model ở đường dẫn google drive.
# Cài đặt gdown
!pip install gdown
# Tải pretrained model về máy
%cd /content
!gdown https://drive.google.com/uc?id=1kZFdvMQt-R7fVebTbfWMk8Op7I9d24so
# Giải nén
!unzip -q vietnamese_wav2vec.zip
Tải dự án từ github. Dự án này Etrain đã fork từ dự án gốc và thêm tập tin inference.py để tùy biến chạy trên colab phục vụ cho việc demo
%cd /content
!git clone https://github.com/etrain-xyz/self-supervised-speech-recognition.git
# Cài đặt thư viện soundfile
!pip install soundfile
Cài đặt torch
Wav2letter không hoạt động với cuda version 11, nên nếu colab của bạn là 11 thì phải chuyển về version 10
!nvcc --version
# Chuyển cuda về version 10.1 nếu version hiện tại là 11
!rm -rf /usr/local/cuda
!ln -s /usr/local/cuda-10.1 /usr/local/cuda
!pip install torchvision==0.7.0
!pip install torch==1.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
Cài đặt fairseq
!pip install fairseq==0.9.0
!pip show fairseq
%cd /content/
!git clone https://github.com/pytorch/fairseq.git
%cd fairseq
!git checkout c8a0659be5cdc15caa102d5bbf72b872567c4859
!pip install --editable ./
!python setup.py build develop


Cài đặt thư viện kenlm
# Cài đặt kenlm
%cd /content/
!git clone https://github.com/kpu/kenlm.git
%cd /content/kenlm/
!mkdir -p build
%cd build
!cmake ..
!make -j 4
Cài đặt thư viện wav2letter
# Cài các gói phụ thuộc
!apt-get update && apt-get upgrade -y && apt-get install -y && apt-get -y install apt-utils gcc libpq-dev libsndfile-dev
!apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
!apt-get install libsndfile1-dev libopenblas-dev libfftw3-dev libgflags-dev libgoogle-glog-dev
# Cài đặt wav2letter
%cd /content/
!rm -rf /content/wav2letter
!git clone -b v0.2 https://github.com/facebookresearch/wav2letter.git
%cd wav2letter/bindings/python
!export KENLM_ROOT_DIR=/content/kenlm/ && pip install -e .
Chạy thử nghiệm
Trong bài demo này Etrain sử dụng dữ liệu tiếng Việt phiên bản Common Voice Corpus 5.1 trên trang Common Voice, để thử nghiệm. Sau khi tải về bạn up lên drive và mount lên colab bạn đang làm việc.
from google.colab import drive
drive.mount("/content/drive", force_remount=True)
Chúng ta sẽ để dữ liệu ở /content/drive/My Drive/Etrain/speech-to-text/vi.tar.gz.
%cd /content/
!tar -xzf '/content/drive/My Drive/Etrain/speech-to-text/vi.tar.gz'
# Tạo thư mục chứa tập tin .wav
!mkdir /content/data
# Tạo thư mục chứa tập tin .mp3
!mkdir /content/mp3_data
Chúng ta sẽ lấy dữ liệu trong tập validated.tsv và chỉ lấy những dữ liệu không có downvote để xem kết quả của model.
import pandas as pd
from shutil import copyfile
validated = pd.read_csv('/content/cv-corpus-5.1-2020-06-22/vi/validated.tsv', sep='\t', usecols=['path', 'sentence', 'up_votes', 'down_votes'])
df = validated[validated['down_votes'] == 0]
for index, row in df.iterrows():
copyfile('/content/cv-corpus-5.1-2020-06-22/vi/clips/' + row['path'], '/content/mp3_data/' + row['path'])
Do model chạy với tập tin có đuôi là wav 16000 bitrate mà dữ liệu trên Common Voide có đuôi là mp3, nên bạn cần phải dùng ffmpeg để convert về định dạng wav.
%cd '/content/mp3_data/'
!for i in *.mp3; do name=`echo "$i" | cut -d'.' -f1` ; ffmpeg -i "${name}.mp3" -acodec pcm_s16le -ac 1 -ar 16000 "/content/data/${name}.wav"; done
Tạo tập tin config.txt để chuẩn bị chạy demo
!rm -f /content/self-supervised-speech-recognition/config.txt
!echo "[TRANSCRIBER]" >> /content/self-supervised-speech-recognition/config.txt
!echo "wav_folder = /content/data" >> /content/self-supervised-speech-recognition/config.txt
!echo "pretrain_model = /content/vietnamese_wav2vec/pretrain.pt" >> /content/self-supervised-speech-recognition/config.txt
!echo "finetune_model = /content/vietnamese_wav2vec/finetune.pt" >> /content/self-supervised-speech-recognition/config.txt
!echo "dictionary = /content/vietnamese_wav2vec/dict.ltr.txt" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_lexicon = /content/vietnamese_wav2vec/lexicon.txt" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_model = /content/vietnamese_wav2vec/lm.bin" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_weight=1.5" >> /content/self-supervised-speech-recognition/config.txt
!echo "word_score=-1" >> /content/self-supervised-speech-recognition/config.txt
!echo "beam_size=50" >> /content/self-supervised-speech-recognition/config.txt
Tập tin config.txt
[TRANSCRIBER]
wav_folder = /content/data
pretrain_model = /content/vietnamese_wav2vec/pretrain.pt
finetune_model = /content/vietnamese_wav2vec/finetune.pt
dictionary = /content/vietnamese_wav2vec/dict.ltr.txt
lm_lexicon = /content/vietnamese_wav2vec/lexicon.txt
lm_model = /content/vietnamese_wav2vec/lm.bin
lm_weight=1.5
word_score=-1
beam_size=50
Cuối cùng là chạy file inference để xem kết quả
%cd /content/self-supervised-speech-recognition/
!python inference.py
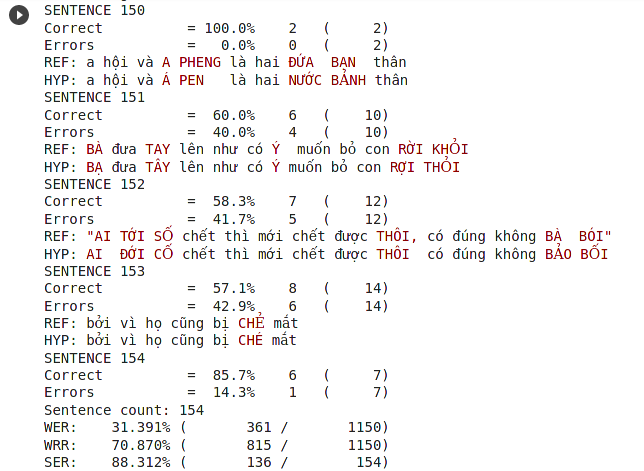
Kết quả sau khi chạy
Mặc định file kết quả sẽ được lưu vào thư mục /content/self-supervised-speech-recognition/result.csv. Ta sử dụng chỉ số WER để đánh giá mô hình. Chỉ số này càng nhỏ thì mô hình càng chính xác. Chúng ta sẽ dùng công cụ asr-evaluation để tính chỉ số này
import os
hypo_df = pd.read_csv('result.csv')
hypo_df['path'] = hypo_df['path'].map(lambda x: os.path.basename(x).split(".wav")[0] + ".mp3")
data_df = pd.merge(df, hypo_df, on='path', how='outer')
data_df['sentence'].str.lower().to_csv('/content/reference.txt', header=False, index=False)
data_df['hypos'].str.lower().to_csv('/content/hypothesis.txt', header=False, index=False)
Sử dụng câu lệnh dưới đây để đánh giá mô hình
!pip install asr-evaluation
!wer -i /content/reference.txt /content/hypothesis.txt