Bài viết này Etrain sẽ sử dụng mã nguồn được sử dụng trong một báo cáo của trường Đại học Manchester để tham gia vào cuộc thi Phát hiện sớm COVID-19 qua tiếng ho do AICovidVN tổ chức.
Dữ liệu cuộc thi bạn có thể tải về trên trang web cuộc thi. Sau khi tải về bạn giải nén các thư mục
%cd /content/
!unzip -q /content/aicv115m_public_train.zip -d ./
!unzip -q /content/aicv115m_public_train/train_audio_files_8k.zip
!unzip -q /content/aicv115m_private_test.zip -d ./
Tải các thư viện cần thiết
import librosa
import librosa.display
from tqdm import tqdm
import pandas as pd
import numpy as np
import os
from sklearn.model_selection import train_test_split
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import optimizers
from tensorflow.keras.utils import plot_model
from datetime import datetime
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import matplotlib
import matplotlib.pyplot as plt
import itertools
import pylab
Xem qua tập tin huấn luyện
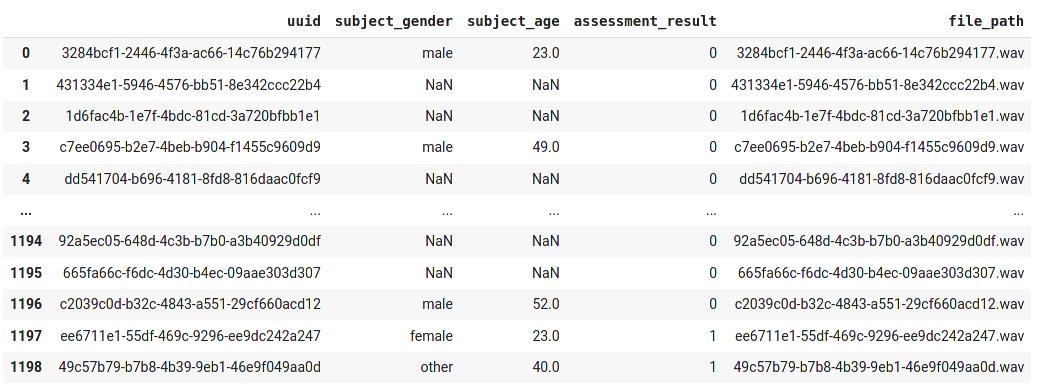
train_df = pd.read_csv("/content/aicv115m_public_train/metadata_train_challenge.csv")
train_df
Bài báo cáo sử dụng thư viện librosa để trích xuất các đặc tính
# Reshape the data
target_names = ['not_covid', 'covid']
num_rows = 120
num_columns = 431
num_channels = 1
def extract_features(file_name):
try:
"""
Load and preprocess the audio
"""
audio, sample_rate = librosa.load(file_name)
y = audio
"""
Convert to MFCC numpy array
"""
max_pad_length = 431
n_mfcc = 120
n_fft = 4096
hop_length = 512
n_mels = 512
mfccs = librosa.feature.mfcc(y=y, sr=sample_rate, n_mfcc=n_mfcc, n_fft=n_fft, hop_length=hop_length, n_mels=n_mels)
pad_width = max_pad_length-mfccs.shape[1]
mfccs = np.pad(mfccs, pad_width=((0,0),(0,pad_width)), mode='constant')
except Exception as e:
print("Error encountered while parsing file: ", e)
return None, sample_rate
return mfccs, sample_rate
mfcc_image_path = "mfcc"
if not os.path.exists(mfcc_image_path):
os.makedirs(mfcc_image_path)
def plot_mfcc(filename, mfcc, sr):
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.amplitude_to_db(mfcc, ref=np.max), y_axis='mel', x_axis='time', sr=sr)
plt.colorbar(format='%+2.0f dB')
plt.title(filename)
plt.tight_layout()
pylab.savefig(os.path.join(mfcc_image_path, filename+'.png'), bbox_inches=None, pad_inches=0)
pylab.close()
def process_dataset(df, PLOT_MFCC):
features = []
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
file_properties = row["file_path"]
file_name = '/content/train_audio_files_8k/'+file_properties
class_label = row["assessment_result"]
data, sr = extract_features(file_name)
if data is not None:
features.append([data, class_label])
# Save an image of the MFCC
if PLOT_MFCC:
plot_mfcc(file_properties+'_'+str(class_label), data, sr)
else:
print("Data is empty: ", file_name)
# Convert into a Panda dataframe
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])
print(featuresdf)
print('Finished feature extraction from ', len(featuresdf), ' files')
# Convert features and corresponding classification labels into numpy arrays
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
return X, y
X, y = process_dataset(train_df, True)
Chia tập dữ liệu thành tập huấn luyện và xác thực
# Split the dataset
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state = 42)
x_train = x_train.reshape(x_train.shape[0], num_rows, num_columns, num_channels)
x_test = x_test.reshape(x_test.shape[0], num_rows, num_columns, num_channels)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)


Khai báo mô hình CNN để phân loại
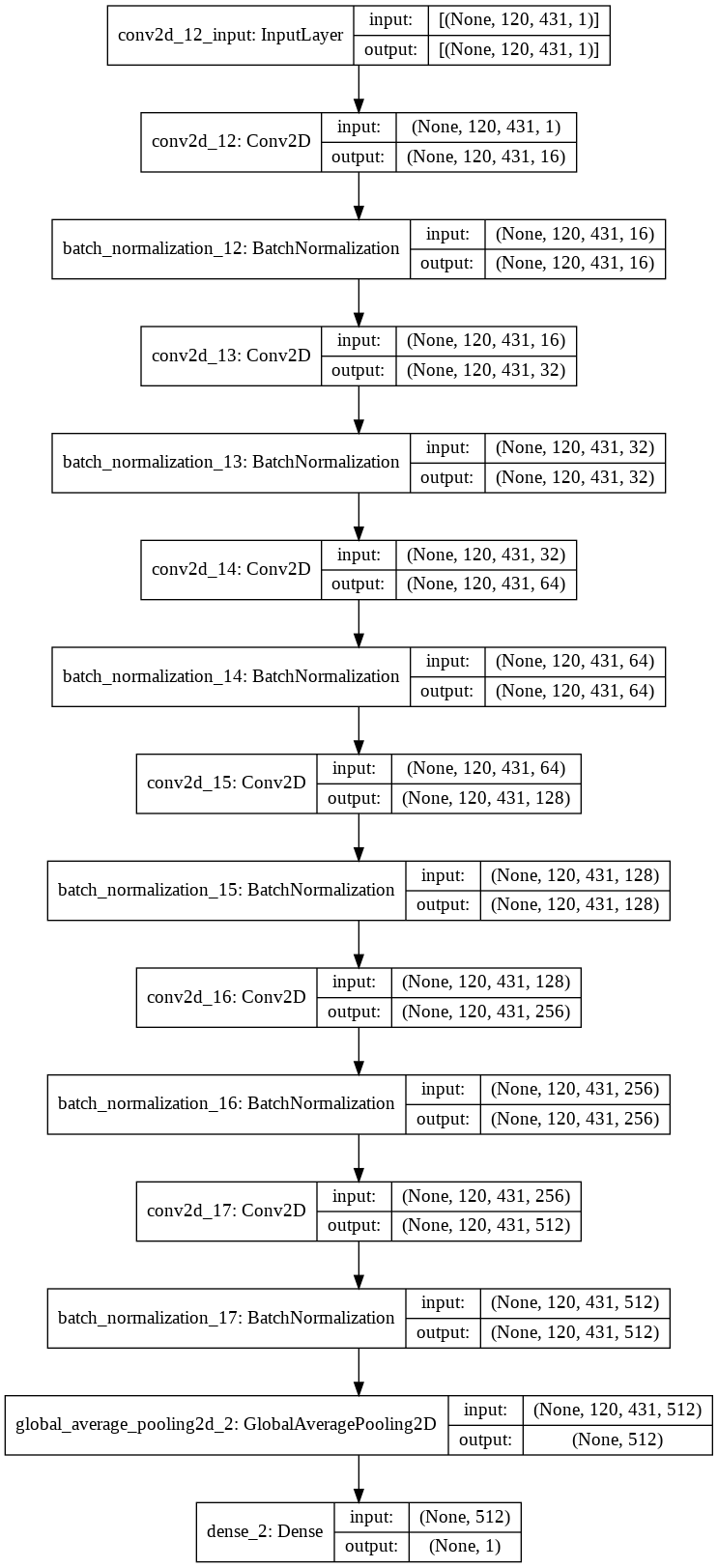
def CNN():
# Construct model
model = Sequential()
model.add(Conv2D(16, (7,7), input_shape=(num_rows, num_columns, num_channels), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(32, (3,3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(64, (3,3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(128, (3,3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(256, (3,3), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(Conv2D(512, (1,1), activation='relu', padding="same"))
model.add(BatchNormalization())
model.add(GlobalAveragePooling2D())
model.add(Dense(1, activation='sigmoid'))
learning_rate = 0.00001
opt = optimizers.Adam(learning_rate=learning_rate)
model.compile(loss='binary_crossentropy', metrics=['accuracy'], optimizer=opt)
model.summary()
return model
cnn_model = CNN()
Huấn luyện dữ liệu
def train_model(model, x_train, x_test, y_train, y_test):
# Calculate pre-training accuracy
score = model.evaluate(x_test, y_test, verbose=1)
accuracy = 100*score[1]
print("Pre-training accuracy: %.4f%%" % accuracy)
# Train the model
num_epochs = 100
num_batch_size = 10
start = datetime.now()
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.basic_cnn.hdf5', verbose=1, save_best_only=True)
es_callback = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.0001, patience=7, verbose=1, mode='auto', min_delta=0.001, cooldown=1, min_lr=0)
history = model.fit(x_train, y_train, batch_size=num_batch_size, epochs=num_epochs, validation_split=0.2, shuffle=False, callbacks = [checkpointer, es_callback], verbose=2)
#history = model.fit(x_train, y_train, batch_size=num_batch_size, epochs=num_epochs, validation_data=(x_test, y_test), shuffle=True, callbacks=[checkpointer], verbose=1)
duration = datetime.now() - start
print("Training completed in time: ", duration)
# Evaluating the model on the training and testing set
score = model.evaluate(x_train, y_train, verbose=0)
print("Training Accuracy: ", score[1])
score = model.evaluate(x_test, y_test, verbose=0)
print("Testing Accuracy: ", score[1])
return history
history = train_model(cnn_model, x_train, x_test, y_train, y_test)
Vẽ biểu đồ kết quả accuracy và loss
mfcc_image_path = "plots"
if not os.path.exists(mfcc_image_path):
os.makedirs(mfcc_image_path)
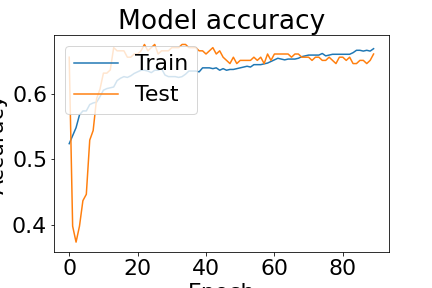
def plot_graphs(history):
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
#plt.show()
plt.savefig('plots/accuracy.png')
plt.clf()
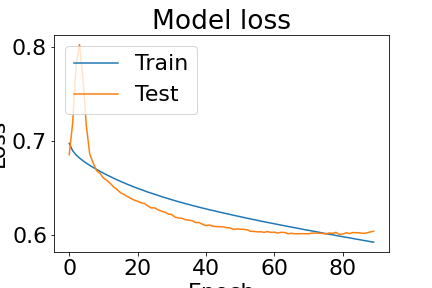
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
#plt.show()
plt.savefig('plots/loss.png')
plt.close()
plot_graphs(history)
Xem biểu đồ confusion_matrix và classification_report
def plot_classification_report(x_test, y_test):
# Print
print(classification_report(x_test, y_test, target_names=target_names))
# Save data
clsf_report = pd.DataFrame(classification_report(y_true = x_test, y_pred = y_test, output_dict=True, target_names=target_names)).transpose()
clsf_report.to_csv('plots/classification_report.csv', index= True)
def plot_confusion_matrix(cm, target_names, title='Confusion matrix', cmap=None, normalize=True):
matplotlib.rcParams.update({'font.size': 22})
accuracy = np.trace(cm) / float(np.sum(cm))
misclass = 1 - accuracy
if cmap is None:
cmap = plt.get_cmap('Blues')
plt.figure(figsize=(14, 12))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
if normalize:
plt.text(j, i, "{:0.4f}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
else:
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label\naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))
plt.savefig('plots/confusion_matrix.png', bbox_inches = "tight")
plt.close()
model = keras.models.load_model('/content/saved_models/weights.best.basic_cnn.hdf5')
y_pred = model.predict(x_train)
predictions = (y_pred > 0.5).astype("int32")
predictions = [p for p in predictions]
cm = confusion_matrix(y_train, predictions)
plot_confusion_matrix(cm, target_names)
plot_classification_report(y_train, predictions)
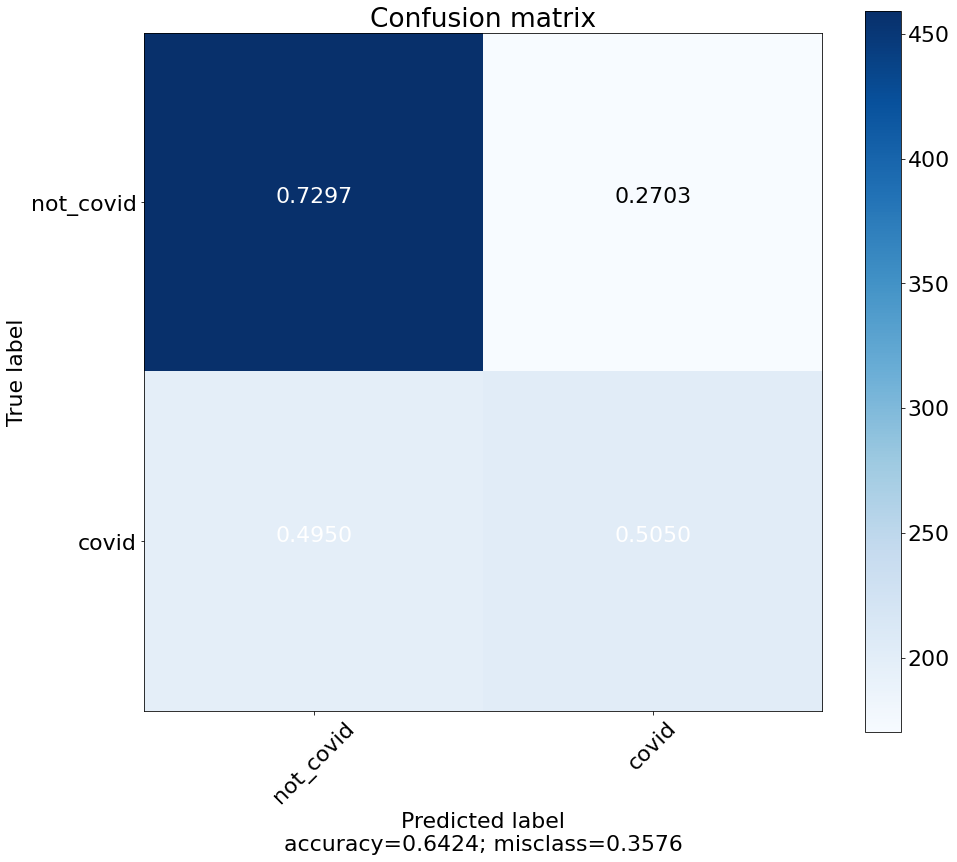
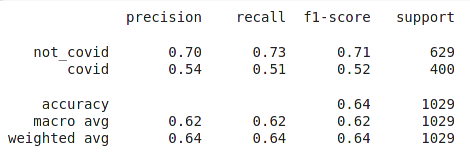
Kết quả với private test ở giai đoạn khởi động là 0.643352
