What is Self-supervised learning
First, we need to know about the self-supervised learning, what problem does it solve.
As manufacturers begin to integrate AI solutions into production lines, data scarcity has emerged as a major competition. Unlike consumer Internet companies, which have data from billions of users to train powerful AI models, collecting massive training sets in manufacturing is often not feasible.
For example, in automotive manufacturing, where lean Six Sigma practices have been widely adopted, most OEMs and Tier One suppliers strive to have fewer than three to four defects per million parts. The rarity of these defects makes it challenging to have sufficient defect data to train visual inspection models.

Big data has enabled AI in consumer internet companies. Can manufacturing also make AI work with small data? In fact, recent advances in AI are making this possible.
The to circumvent the small data problem to help their AI projects go live even with only dozens or fewer examples. Self-supervised learning is one of the techniques that circumvent the small data problem to help their AI projects go live even with only dozens or fewer examples.
Self-supervised learning is similar to transfer-learning, but the obtained knowledge is acquired by solving a slightly different task and then adapted to small data problem. For example, you can take a lot of OK images and create a puzzle-like grid to be sorted by a base model. Solving this dummy problem will force the model to acquire domain knowledge that can be used as starting point in the small data task.
Using for the Vietnamese speech to text problem
“Self-supervised speech recognition with limited amount of labeled data” is a repo using the self-supervised learning for the speech to text problem. We will test with the Vietnamese pretrained-model.

You access Google Colab and create new notebook. Download the pretrained-model at google drive.
# Install gdown
!pip install gdown
# Download pretrained model
%cd /content
!gdown https://drive.google.com/uc?id=1kZFdvMQt-R7fVebTbfWMk8Op7I9d24so
# Unzip
!unzip -q vietnamese_wav2vec.zip
Clone the Etrain repo. This repo is forked from the original repo. The goal was to ensure the demo running on Colab.
%cd /content
!git clone https://github.com/etrain-xyz/self-supervised-speech-recognition.git
# Install soundfile lib
!pip install soundfile
Install torch
Wav2letter does not work with cuda v11. You need downgrade to cuda v10
!nvcc --version
# Downgrade to v10.1 if the current version is 11
!rm -rf /usr/local/cuda
!ln -s /usr/local/cuda-10.1 /usr/local/cuda
!pip install torchvision==0.7.0
!pip install torch==1.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
Install fairseq
!pip install fairseq==0.9.0
!pip show fairseq
%cd /content/
!git clone https://github.com/pytorch/fairseq.git
%cd fairseq
!git checkout c8a0659be5cdc15caa102d5bbf72b872567c4859
!pip install --editable ./
!python setup.py build develop
Install kenlm
# Install kenlm
%cd /content/
!git clone https://github.com/kpu/kenlm.git
%cd /content/kenlm/
!mkdir -p build
%cd build
!cmake ..
!make -j 4
Install wav2letter
# Install dependencies
!apt-get update && apt-get upgrade -y && apt-get install -y && apt-get -y install apt-utils gcc libpq-dev libsndfile-dev
!apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
!apt-get install libsndfile1-dev libopenblas-dev libfftw3-dev libgflags-dev libgoogle-glog-dev
# Install wav2letter
%cd /content/
!rm -rf /content/wav2letter
!git clone -b v0.2 https://github.com/facebookresearch/wav2letter.git
%cd wav2letter/bindings/python
!export KENLM_ROOT_DIR=/content/kenlm/ && pip install -e .
Inference
We use the Common Voice Corpus 5.1 dataset in Common Voice for this demo. Download the dataset and upload to your drive and mount the directory in drive to colab.
from google.colab import drive
drive.mount("/content/drive", force_remount=True)
The dataset file path is "/content/drive/My Drive/Etrain/speech-to-text/vi.tar.gz". Unzip file to Colab and make data directories
%cd /content/
!tar -xzf '/content/drive/My Drive/Etrain/speech-to-text/vi.tar.gz'
# Make the directory containing wav audio
!mkdir /content/data
# Make the directory containing mp3 audio
!mkdir /content/mp3_data
In the validated.tsv file, we get all data with down_votes=0
import pandas as pd
from shutil import copyfile
validated = pd.read_csv('/content/cv-corpus-5.1-2020-06-22/vi/validated.tsv', sep='\t', usecols=['path', 'sentence', 'up_votes', 'down_votes'])
df = validated[validated['down_votes'] == 0]
for index, row in df.iterrows():
copyfile('/content/cv-corpus-5.1-2020-06-22/vi/clips/' + row['path'], '/content/mp3_data/' + row['path'])
Convert the audio data format from mp3 to wav using ffmpeg
%cd '/content/mp3_data/'
!for i in *.mp3; do name=`echo "$i" | cut -d'.' -f1` ; ffmpeg -i "${name}.mp3" -acodec pcm_s16le -ac 1 -ar 16000 "/content/data/${name}.wav"; done
Make config.txt to run demo
!rm -f /content/self-supervised-speech-recognition/config.txt
!echo "[TRANSCRIBER]" >> /content/self-supervised-speech-recognition/config.txt
!echo "wav_folder = /content/data" >> /content/self-supervised-speech-recognition/config.txt
!echo "pretrain_model = /content/vietnamese_wav2vec/pretrain.pt" >> /content/self-supervised-speech-recognition/config.txt
!echo "finetune_model = /content/vietnamese_wav2vec/finetune.pt" >> /content/self-supervised-speech-recognition/config.txt
!echo "dictionary = /content/vietnamese_wav2vec/dict.ltr.txt" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_lexicon = /content/vietnamese_wav2vec/lexicon.txt" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_model = /content/vietnamese_wav2vec/lm.bin" >> /content/self-supervised-speech-recognition/config.txt
!echo "lm_weight=1.5" >> /content/self-supervised-speech-recognition/config.txt
!echo "word_score=-1" >> /content/self-supervised-speech-recognition/config.txt
!echo "beam_size=50" >> /content/self-supervised-speech-recognition/config.txt
The config.txt file
[TRANSCRIBER]
wav_folder = /content/data
pretrain_model = /content/vietnamese_wav2vec/pretrain.pt
finetune_model = /content/vietnamese_wav2vec/finetune.pt
dictionary = /content/vietnamese_wav2vec/dict.ltr.txt
lm_lexicon = /content/vietnamese_wav2vec/lexicon.txt
lm_model = /content/vietnamese_wav2vec/lm.bin
lm_weight=1.5
word_score=-1
beam_size=50
Run the inference and see the results
%cd /content/self-supervised-speech-recognition/
!python inference.py
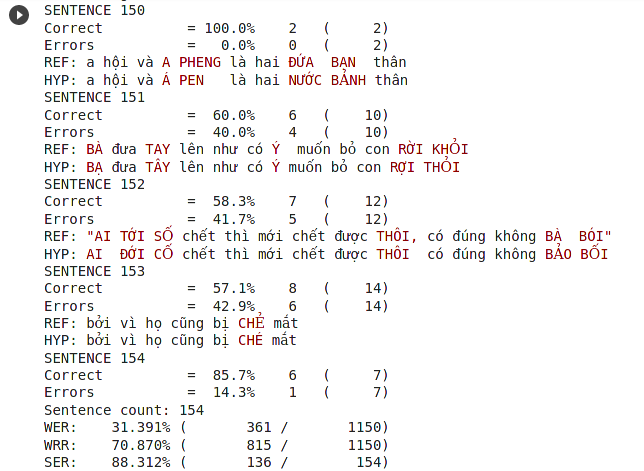
The results
The default result location is /content/self-supervised-speech-recognition/result.csv. The most common metric for speech recognition accuracy is called word error rate (WER). The lower the WER, the more accurate the system. We use asr-evaluation tool to calculate the wer metric.
import os
hypo_df = pd.read_csv('result.csv')
hypo_df['path'] = hypo_df['path'].map(lambda x: os.path.basename(x).split(".wav")[0] + ".mp3")
data_df = pd.merge(df, hypo_df, on='path', how='outer')
data_df['sentence'].str.lower().to_csv('/content/reference.txt', header=False, index=False)
data_df['hypos'].str.lower().to_csv('/content/hypothesis.txt', header=False, index=False)
Use the following command to compare the reference and hypothesis text files that you created
!pip install asr-evaluation
!wer -i /content/reference.txt /content/hypothesis.txt