Chuẩn bị dữ liệu
Bài viết sử dụng EfficientNetV2 để phân loại người bị viêm phổi có phải do covid hay không. Dữ liệu được lấy từ cuộc thi trên kaggle
Dữ liệu ảnh là file có định dạng DICOM, trong bài viết này Etrain sẽ sử dụng sẵn dữ liệu đã được chuyển thành JPG được tải về tại notebook này
Trong phần Input tải về train_image_level.csv và train_study_level.csv. Phần output thì tải về meta.csv và train.tar.gz. Ở đây etrain sẽ để toàn dữ liệu trên drive và sẽ có cấu trúc như sau
siim-covid
|-- train_image_level.csv
|-- train_study_level.csv
|-- train.tar.gz
|-- meta.csv
Giải nén thư mục train.tar.gz
!tar xzf file.tar.gz
Tạo dữ liệu huấn luyện cho model từ các dataframe
import pandas as pd
train_image_level = pd.read_csv("/content/drive/MyDrive/Etrain/siim-covid/train_image_level.csv")
train_study = pd.read_csv('/content/drive/MyDrive/Etrain/siim-covid/train_study_level.csv')
# merge study csv
train_study['StudyInstanceUID'] = train_study['id'].apply(lambda x: x.replace('_study', ''))
del train_study['id']
train = train_image_level.merge(train_study, on='StudyInstanceUID')
train = train.rename(columns={
'Negative for Pneumonia': 'negative',
'Typical Appearance': 'typical',
'Indeterminate Appearance': 'indeterminate',
'Atypical Appearance': 'atypical'
})
def get_image_name(image_id):
image_name = image_id.split("_image")[0] + ".jpg"
return image_name
train["image"] = train["id"].apply(get_image_name)
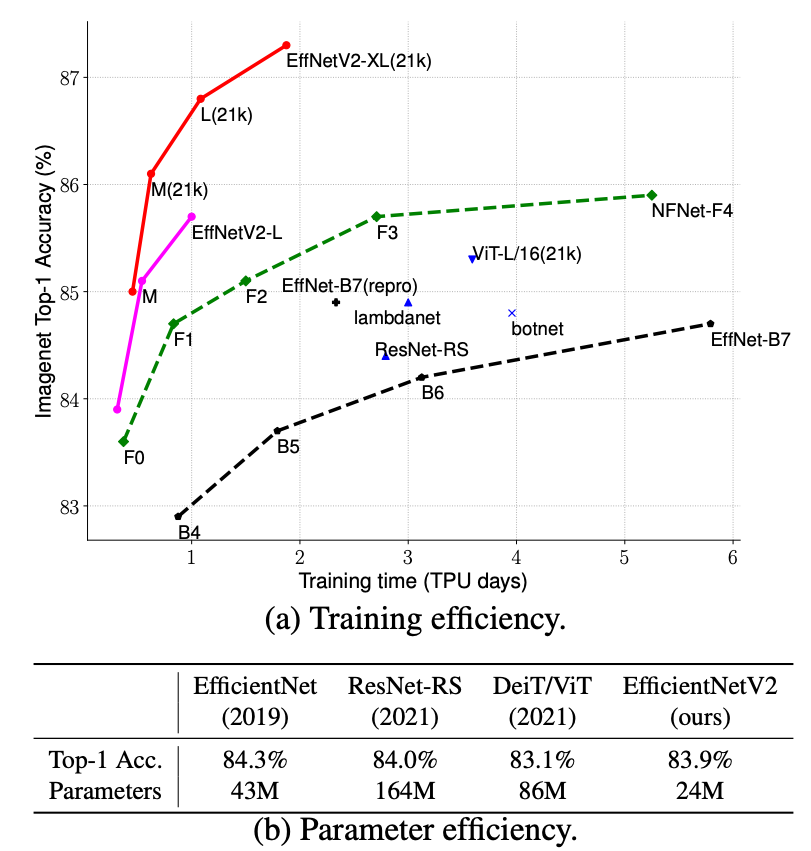
EfficientNetV2
Bài viết sử dụng mô hình EffNetV2-L và sử dụng pretrain efficientnetv2-l-21k-ft1k
import tensorflow as tf
import tensorflow_hub as hub
print('TF version:', tf.__version__)
print('Hub version:', hub.__version__)
print('Phsical devices:', tf.config.list_physical_devices())
# Build model
hub_url = 'gs://cloud-tpu-checkpoints/efficientnet/v2/hub/efficientnetv2-l-21k-ft1k/feature-vector'
image_size = 480
batch_size = 4
labels = ["negative", "typical", "indeterminate", "atypical"]
tf.keras.backend.clear_session()
model = tf.keras.Sequential([
# Explicitly define the input shape so the model can be properly
# loaded by the TFLiteConverter
tf.keras.layers.InputLayer(input_shape=[image_size, image_size, 3]),
hub.KerasLayer(hub_url, trainable=True),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(
len(labels),
kernel_regularizer=tf.keras.regularizers.l2(0.0001),
activation='sigmoid'
)
])
model.build((None, image_size, image_size, 3))
model.summary()

Sử dụng ImageDataGenerator để tạo dữ liệu huấn luyện và xác thực theo tỷ lệ 80% huấn luyện và 20% xác thực. Chúng ta sẽ tăng dữ liệu huấn luyện bằng cách sử dụng 2 phương pháp là lật ảnh theo chiều dọc và chiều ngang.
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
dataflow_kwargs = dict(target_size=(image_size, image_size),
batch_size=batch_size)
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
**datagen_kwargs)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
image_path = '/content/drive/MyDrive/Etrain/siim-covid/train'
train_generator = train_datagen.flow_from_dataframe(
train,
directory=image_path,
shuffle=True,
class_mode="raw",
color_mode="rgb",
x_col="image",
y_col=labels,
subset="training",
**dataflow_kwargs
)
valid_generator = valid_datagen.flow_from_dataframe(
train,
directory=image_path,
shuffle=False,
class_mode="raw",
color_mode="rgb",
x_col="image",
y_col=labels,
subset="validation",
**dataflow_kwargs
)


Huấn luyện dữ liệu và lưu model với val_loss nhỏ nhất
model_checkpoint = tf.keras.callbacks.ModelCheckpoint(
filepath="/content/drive/MyDrive/Etrain/siim-covid/efficientnetv2-l-21k-ft1k-study-level.h5",
monitor='val_loss',
save_best_only=True,
verbose=1,
mode='min'
)
model.compile(
optimizer=tf.keras.optimizers.SGD(learning_rate=0.005, momentum=0.9),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False, label_smoothing=0.1),
metrics=['accuracy']
)
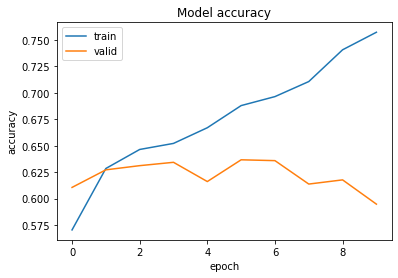
hist = model.fit(
train_generator,
epochs=num_epochs,
validation_data=valid_generator,
callbacks=[model_checkpoint]).history
import matplotlib.pyplot as plt
plt.plot(hist['accuracy'])
plt.plot(hist['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'valid'], loc='upper left')
plt.show()
Bạn có thể xem hướng dẫn trong notebook này để xem kết quả dự đoán của model
